Attacking Merkle Trees With a Second Preimage Attack
(Thanks to @mah3mm for sparking curiosity then schooling me on this)
This post will outline a common flaw in implementations of Merkle Trees, with demonstrations of potential attacks against the most popular python libraries.
But first, a brief overview of what both a Merkle Tree and a Second Preimage attack are.
Merkle Trees
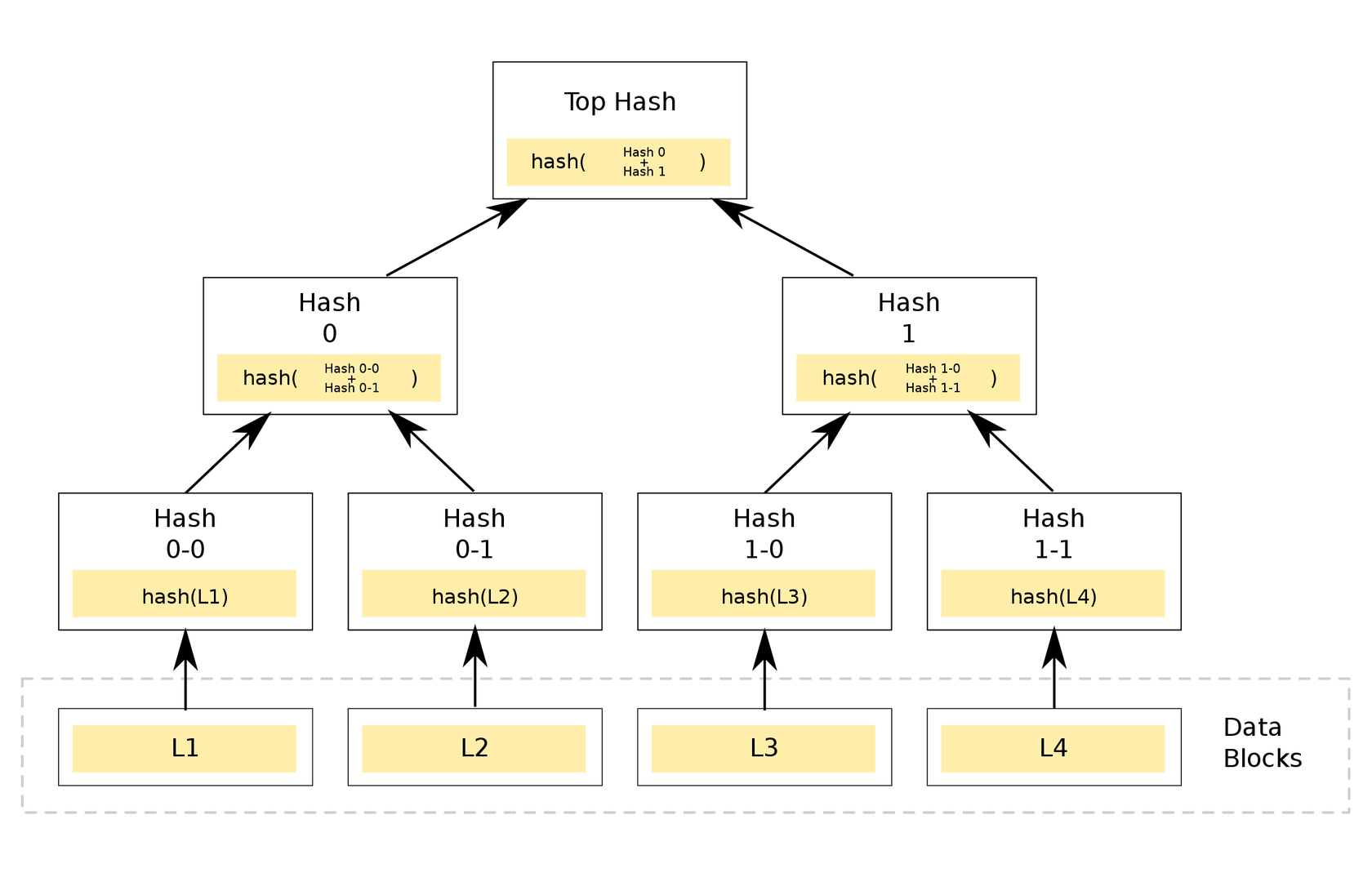
A Merkle Tree is a fairly simple data structure that allows chunks of data (whether originally in chunks such as files, or that have been intentionally broken up into chunks) to have a hash calculated across all of the data in an independent and distributed manner.
To use an example: if you have 2000 1GB files, and want to calculate the SHA256 of your data, you’d typically concatenate all the files together and take a single hash value of that data. This is problematic for a number of reasons – including the fact that if a single byte in a single file changes, you’d need to run another SHA256 hash over 2TB of data. Second, you couldn’t calculate your hash until you had all 2000 files, at which point you’d be starting from scratch.
A Merkle Tree solves this by hashing individual chunks of data (keeping with the above example, each 1GB file), and then constructing a binary tree of the hashes until you’re left with only a single hash value, representing the entirety of your chunks of data. This means that if a single file changes, you only have to re-hash that file, and then calculate hashes of hashes which is a very fast operation.
A picture and the wikipedia page for Merkle Trees is worth a thousand words:
Second Preimage attacks
A Preimage Attack is where you are given a hash fingerprint and your task is to find any data hashes to that value.
For example, if I gave you the MD5 value 5EB63BBBC01EEED093CB22BB8F5ACDC3 and you could discover data that generates that hash, you’ve broken MD5 with a Preimage Attack.
Side note: MD5 is a 128-bit hash function, and the best Preimage attacks against it reduce it’s strength to 123 bits, which is still very strong against Preimage Attacks. The significant weakness that has caused MD5 to be deprecated is a Collision Attack, where an attacker can generate two inputs that both hash to the same hash value, but isn’t controllable or predictable.
A Second Preimage Attack is where you are given some data and your task is to find a second set of data which generates the same hash as the first. It’s very similar yet subtly different to a regular Preimage Attack in that you have a sample of data that you know leads to the target hash value. A Second Preimage is always more difficult to perform than a collision, as one input is outside of the attackers control.
A Second Preimage Attack against Merkle Trees
The attack against Merkle Trees is quite simple once you get your head around it. The assumption that a lot of implementations make is that if you pass a series of inputs into a Merkle Tree and get a root hash value out, there are no other inputs that could lead to that hash value. This is wrong in many implementations because of a minor flaw.
In the above example, our inputs are L1, L2, L3, and L4. These eventually output the root hash value at the top of the diagram. But as you can see from the diagram, the inputs to the middle layer are the concatenated hashes of the previous layer, and we can just pass those two values directly into the Merkle Tree and get the same root hash value back.
An important note is that this attack can occur even if the underlying hash function has no known security weaknesses: it is inherently a problem in how many Merkle Tree’s are constructed.
This is much more vivid if an example is used, as follows.
Example Attacks
Instead of explaining this attack with sample code, I googled “python merkle tree”, and worked my way through the github repos with MT implementations, and wrote simple PoC code to demonstrate the flaw.
The first example is https://github.com/JaeDukSeo/Simple-Merkle-Tree-in-Python
First, we’ll import the Merkle Tree implementation and json library for printing output. I’ve then made a simple function to construct an MT object, assign a series of ‘transactions’ (chunks of data), finally constructing the tree out of this data and then printing the root node, as well as dumping the tree values which will show how we got to this root node.
import json
from MerkleTrees import Jae_MerkTree
def do_merktree(transactions):
Jae_Tree = Jae_MerkTree()
Jae_Tree.listoftransaction = transactions
Jae_Tree.create_tree()
past_transaction = Jae_Tree.Get_past_transacion()
print "final root: %s" % (Jae_Tree.Get_Root_leaf())
print(json.dumps(past_transaction, indent=4))This is where we actually demonstrate three values passed into this implementation which will all output the exact same hash value:
transaction1 = ['a','b','c','d']
transaction2 = ['ca978112ca1bbdcafac231b39a23dc4da786eff8147c4e72b9807785afee48bb3e23e8160039594a33894f6564e1b1348bbd7a0088d42c4acb73eeaed59c009d','2e7d2c03a9507ae265ecf5b5356885a53393a2029d241394997265a1a25aefc618ac3e7343f016890c510e93f935261169d9e3f565436429830faf0934f4f8e4']
transaction3 = ['62af5c3cb8da3e4f25061e829ebeea5c7513c54949115b1acc225930a90154dad3a0f1c792ccf7f1708d5422696263e35755a86917ea76ef9242bd4a8cf4891a']
do_merktree(transaction1)
do_merktree(transaction2)
do_merktree(transaction3)In transaction1, I pass in four values: a, b, c, d
In transaction2, I pass in two values, each of which is the concatenation of the hashes of two prior values – for example, hash(a)+hash(b) and hash(c)+hash(d) where I’m using a plus symbol for concatenation.
In transaction3, I pass in one value: the concatenation of the hashes output from the previous layer.
The output (with full tree dumping commented out) looks like so:
('final root: ', '58c89d709329eb37285837b042ab6ff72c7c8f74de0446b091b6a0131c102cfd')
('final root: ', '58c89d709329eb37285837b042ab6ff72c7c8f74de0446b091b6a0131c102cfd')
('final root: ', '58c89d709329eb37285837b042ab6ff72c7c8f74de0446b091b6a0131c102cfd')The second example is: https://github.com/Tierion/pymerkletools and can be installed with “pip install merkletools”. The following code follows a similar trend, and is somewhat self explanatory.
import merkletools
mt = merkletools.MerkleTools(hash_type='md5')
mt.add_leaf(['a','b','c','d'],True)
mt.make_tree()
print("%s") % (mt.get_merkle_root())
mt.reset_tree()
mt.add_leaf('96e024ba2074fe77e8e965ba43a704be')
mt.add_leaf('c0a594722e66ed5e4dec538fdc1fc1ba')
mt.make_tree()
print("%s") % (mt.get_merkle_root())This produces the following output:
$ python2 merkletools_demo.py
ec3b15651156ce266ed7d267d8d43349
ec3b15651156ce266ed7d267d8d43349We’ve successfully provided two different inputs to the tree which have resulted in the same hash fingerprint being calculated.
Limitations of this attack
The significant limitation and reason that these attacks often aren’t actually of concern in the real world (such as with bitcoin) is that whilst we can find input Y which generates the same hash value as input X, we have zero control over the value of Y or even its format, meaning our input will likely not be interpreted in a useful manner to whatever application is relying upon the Merkle Tree for data integrity. One likely attack this could lead to is a Denial of Service, where data could be overwritten or replaced because the integrity is not guaranteed by matching the hash value.
How to Fix
Fortunately, the fix for this is fairly simple. The idea is to differentiate between leaf nodes and intermediate nodes in the tree by prepending a different byte value for leaf and intermediate nodes (such as 0x00 and 0x01 as in the certificate transparency implementation). Alternatively, tree depth or node depth can be recorded as part of the data structure, meaning that an attacker can’t just supply intermediate values directly.